jdk LinkedList工作原理分析
List接口的实现类之一ArrayList的内部实现是一个数组,而另外一个实现类LinkedList的内部实现是使用双向链表。
继承结构
1 | public class LinkedList<E> |
LinkedList是一个继承于AbstractSequentialList的双向链表。可以被当作双端队列进行操作。
LinkedList是非同步的。
成员变量
1 | //链表的节点数量 |
我们看下node的节点定义。
Node结构
1 | private static class Node<E> { |
构造函数
LinedList有一个无参的构造函数,和一个集合参数构造函数。
1 | public LinkedList() { |
方法
我们还是挑选几个主要的方法讲解一下。
boolean add(E e)
添加元素到链表的最后位置
1 | public boolean add(E e) { |
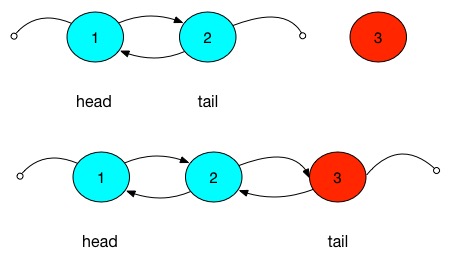
上图第一个图表示已经有1,2节点的LinkedList调用add方法,第二个图表示添加一个节点3后的情况。
原先尾节点的下一个节点变为节点3,新节点3的前节点变为原先的尾节点2,新节点的后节点为null,同时链表的尾节点变为节点3
void add(int index, E element)
添加元素到链表中的指定位置
1 | public void add(int index, E element) { |
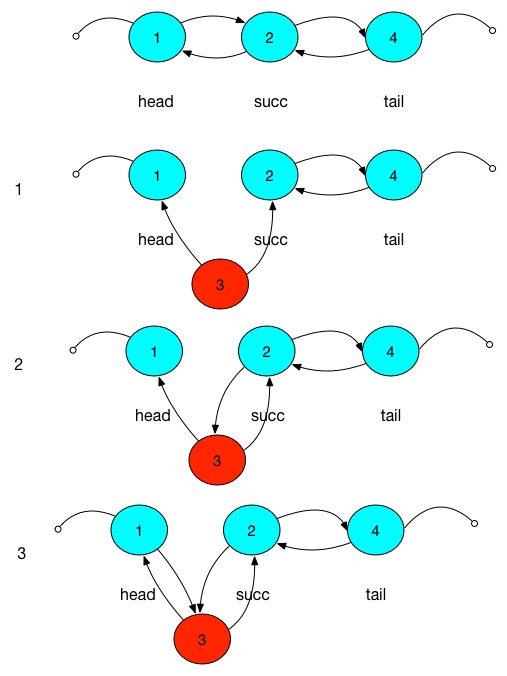
上面图中的1,2,3对应下图
E remove(int index)
移除指定位置上的节点
1 | public E remove(int index) { |
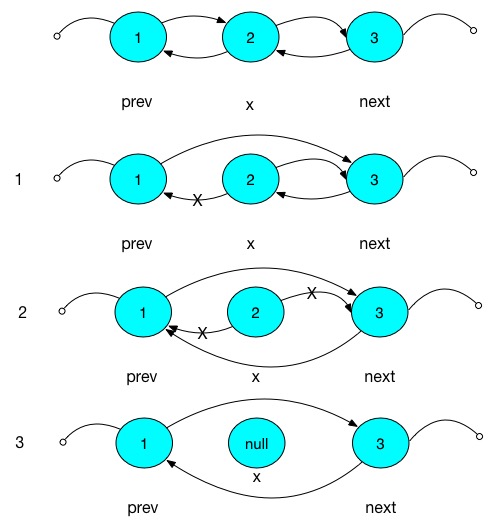
上面代码中的1,2,3在如图中表示
E get(int index)
获取索引位置上的元素
1 | public E get(int index) { |
ListIterator listIterator(int index)
返回一个双向的迭代器
1 | public ListIterator<E> listIterator(int index) { |
LinkedList和ArrayList的比较
1.两者的设计理念不同,ArrayList是基于数组,而LinkedList基于节点,也就是链表。所以LinkedList没有容量的概念。
2.两者的使用场景不同。ArrayList适用于读多写少的场景,LinkedList适用于写多读少的场景。
因为LinkedList要找到节点的必须要遍历一个一个的节点,直到找到为止。而ArrayList完全不需要,因为ArrayList内部维护一个数组,直接根据索引找到需要的元素就好了。