Elasticsearch术语及概念
集群(cluster)
集群由一个或多个节点组成,对外提供索引和搜索功能。在所有节点,一个集群会有一个唯一的名称标识,当该节点被设置为相同的集群名称时,就会自动加入集群。
请注意,一个节点只能加入一个集群。
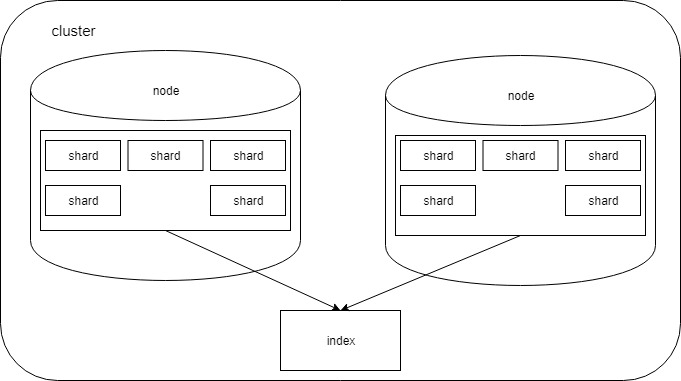
节点(node)
一个节点是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能。就像集群一样,节点也有唯一的名字,在网络中Elasticsearch集群通过节点名称进行管理和通信。
一个节点可以被配置加入一个特定的集群。相同集群名的多个节点的连接就组成了一个集群。
默认情况下,集群中每个节点都可以处理HTTP请求和集群节点的数据传输。集群中所有节点都知道集群中其他的所有节点,可以将客户端请求转发到适当的节点。
节点有以下类型:
主(master)节点:主要职责是轻量级的集群操作内容,比如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关节点。索引和查询数据会占用大量的CPU、内存、IO资源,默认情况下,节点同时是主节点和数据节点,为了确保集群稳定,分离主节点和数据节点是必要的。(尽可能做少量的工作。
主节点的配置如下:
1
2
3
4node.master: true //就有资格被选为主节点
node.data: false
node.ingest: false
cluster.remote.connect: false //跨集群搜索数据(data)节点:主要是存储索引数据的节点,主要对文档进行增删改查、聚合操作等。
数据节点的配置如下:
1
2
3
4node.master: false
node.data: true
node.ingest: false
cluster.remote.connect: false
客户端(client)节点:当客户端节点和数据节点都设置为false时,该节点只能处理路由请求,处理搜索,分发索引操作等,像一个智能的负载平衡器。独立的客户端节点在一个比较大的集群中时非常有用的,它协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接发送路由请求。
配置如下:
1
2
3
4node.master: false
node.data: false
node.ingest: false
cluster.remote.connect: false预处理(ingest)节点:在索引数据前可以先对数据做预处理操作。
1
2
3
4node.master: false
node.data: false
node.ingest: true
cluster.remote.connect: false机器学习(machine learning)节点:具有xpack.ml.enable和node.xml设置为true的节点。如果要使用机器学习的功能,则集群中必须至少有一个机器学习节点。
路由(routing)
当存储一个文档的时候,它会存储在唯一的主分片中,具体哪个分片是通过散列值进行选择。默认情况下,这个值是由文档的ID生成。如果文档有一个指定的父文档,则从父文档ID中生成,该值可以在存储文档的时候修改。
1 | shard = hash(routing) % number_of_primary_shards // routing值默认是文档的_id,number_of_primary_shards是索引的主分片个数 |
分片(shard)
分片就是对数据切分成多个部分,索引存储的时候并不是整个存一起的,它是被分片存储的。分片是数据的容器,数据保存在分片内,分片又被分配到集群内的各个节点。Elasticsearch会自动管理集群中的所有分片,当发生故障的时候,Elasticsearch会把分片移动到不同的节点或者添加新的节点。
一个索引可以存储很大的数据,这些空间可以超过一个节点的物理限制。
例如:十亿个文档占用磁盘空间为1TB,仅从单个节点搜索可能会很慢,还有一台物理机器也不一定能存储这么多的数据。那怎么办呢?Elasticsearch将索引分解成多个分片。当创建索引的时候,可以自定义分片数量,每个分片是一个独立单元,可以托管在集群的任何节点。
索引指向主分片和副本分片的逻辑空间。
分片主要有两个重要原因:
- 允许水平分割扩展数据
- 允许分配和并行操作(可能在多个节点)从而提高性能和吞吐量
主分片(primary shard)
每个文档都存储在一个分片中,当存储一个文档的时候,系统会首先存储在主分片中,然后复制到不同的副本中。
默认情况下,一个索引有5个分片,当分片一旦建立,则分片的数量不能修改。
副本分片(replica shard)
每个分片有零个或多个副本。
副本主要是主分片的复制,其中有两个目的:
- 增加高可用性:当某台主机宕机的时候,我们依然可以从另一台主机的副本中找到相应的数据。
- 提升性能:当查询的时候可以到主分片和副本分片中进行查询。默认情况下一个主分片配有一个副本,但副本的数量可以在后面动态的配置增加。
默认情况下,每个索引分配5个分片和一个副本,也就是说你的集群节点至少要有两个节点,你将拥有5个主要分片和5个副本分片共计10个分片。
集群健康状态
green:所有的主分片(Primary Shard)和副本分片(Replica Shard)都处于活动状态。
yellow:所有的主分片都处于活跃状态,但是并不是所有的副本分片都处于活动状态。
red:不是所有的主分片都处于活动状态。
资料:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html