大型网站性能监控体系
为什么要做监控
昨天下午,公司发生一起大批量创建订单异常事故,影响单量1600单左右,时长约8分钟,如果按照客单量500RMB计算,显然这是一笔不小的数目,是一起S1级的事故了。
大型网站的用户访问量在数量级上比小型网站大得多,一旦发生问题,对于业务的影响将非常大。
像淘宝、天猫这样的交易型网站,数分钟的不可用可能造成数亿甚至数十亿的损失。
大型网站的运行需要一个完善的监控体系,监控的根本目的是发现问题并定位问题,是性能优化的基础。
监控设计
从问题排查思路看监控设计
问题发现
通过监控能够直接判断出是否出了问题,是否对业务有影响,从这个角度来看,首先要考虑部署业务监控的能力,对业务的关键指标进行监控,同时根据业务周期性规律进行环比、同比的报警规则设置,出现对业务有直接影响的问题要立即报警。
定位问题
首先排查应用是否产生了大量异常,当业务有损伤时,会看是否是应用本身出现问题了。
其次看关键链路的调用次数是否变少了,
可能原因之一,外部流量减少。
- 正常业务的影响:活动或者节假日影响。
- 网络链路加入异常:如外部接入核心交换,通常多个运行商接入,某些运营商出现网络问题,这个问题一旦出现会导致整体流量下滑。
可能原因之二:链路耗时变长,导致一定时间内处理的请求数变少了。
- 交换机流量不均,某些机器的流量被打满,TCP重试,导致耗时边长。
- 服务器流量不均
- 应用集群个体异常,某些服务器存在问题。
- 集群系统指标个体异常,集群中个别服务器存在问题,可能配置不同
- 依赖方个体异常,某些依赖存在问题,导致访问异常
监控的设计步骤
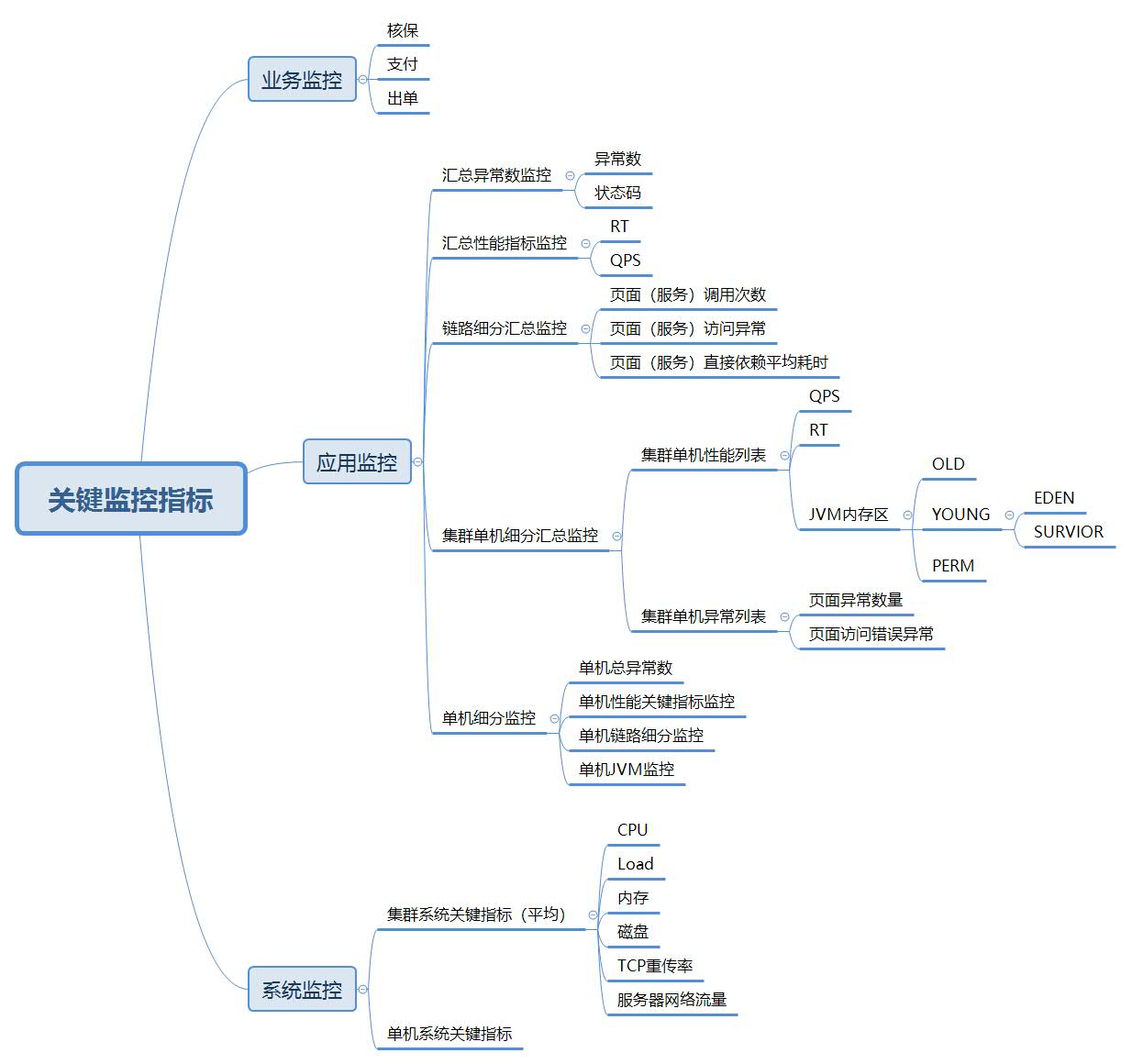
关键监控项梳理
关键监控项报警
- 临界点报警
- 业务预警做重点关注报警,可以通过短信方式预警
监控布点开发和设计
监控需要各种数据的支持。布点要和关键指标关联。
- 捕获关键异常,对关键异常进行日志记录,分级。
- 对直接依赖的运行耗时进行日志记录。
- 对反应业务指标的运行情况进行日志记录。
- 正确处理错误码。
监控展现设计
趋势化的监控比列表型展现更一目了然。
确定合适的监控粒度,长段间距相结合。
从粗到细,从汇总到细分的监控。
监控体系设计的目标和原则
准确性
- 监控系统应该一直持续可用。
- 监控系统应该保持数据的准确性
完整性
在诊断过程中,需要把几乎所有需要的监控项监控完整
实时性
问题发生时要及时发现,避免因为监控的架构设计问题造成发现问题延迟。
细分性
细分化对于排查系统的瓶颈、追踪系统问题是非常关键的。
聚合化
大型网站往往有数千台服务器,一个大型的应用集群可能需要上千台机器,查看这些机器的汇总表现非常重要。
图标化
将数字化的东西用图形的方式展示,人们通过图标很容易看到发生问题。
可追溯
有些问题准瞬即逝,模拟和重现非常困难,因此监控结果需要保留一段时间。
性能监控的关键指标
应用监控
QPS
QPS(Query per Second)表示每秒处理完成的请求数,是衡量系统吞吐量大小或者系统处理能力的指标,服务器的QPS越高,提供服务需要的机器就越少。每个系统都有自己的峰值QPS,表示系统最大的吞吐量。
在做容量规划的时,峰值QPS作为容量规划的一个主要因子,来计算需要多少台机器。可以根据一定的数学计算得出业务访问需要多少QPS,再除以Peak QPS,就可以得出需要的机器数量。
注:QPS和TPS是有区别的,TPS是每秒处理完成事务的过程数,一个请求可能包含多个事务处理过程。对于web请求而言,一个单独的请求算作一个query,所以通常QPS是衡量服务器性能的主要指标。
RT
RT(Response Time)表示响应时间,它是从接收请求开始到服务器处理完成的时间差值。
减少RT的方法,要么合并请求,将多次调用合并成一次调用,要么减少调用。减少远程接口调用,可以通过缓存架构升级或者去除多于调用来实现。
并发数
并发数是衡量系统压力的指标,并发数越大,系统压力越大。
一般并发数是针对某个具体的链路而言的,并发数是同时在处理或者需要处理的任务数或者线程数。
以上三个指标是最终系统运行中性能的表现,是各种资源综合作用的结果,与应用本身程序编写的问题、应用本身的特点和应用本身的架构都密切相关。
异常监控
通常服务器端出现峰值时会出现一些异常,这些异常主要是程序本身的异常,最常见的异常包括RPC连接池异常、数据库连接池异常、超时异常、JVM异常。
通常在单机或者集群进行压力测试时,异常作为停止的指标。
URL 监控
URL是WEB应用通常需要监控的,包含以下关键指标:
- 调用量
- 耗时
- 错误数
- 相关依赖明细
- 状态码
- 并发数
关键方法监控
服务或者中间件,需要监控以下指标:
- 耗时
- 依赖明细
- 异常
- 并发数
JVM监控
- 分区监控
- 垃圾回收次数
- 垃圾回收时间
系统监控
CPU资源监控
CPU是是操作系统的调度中枢,是影响服务器端吞吐量的最重要因素。
服务器峰值的处理能力取决于CPU的利用率和CPU的处理时间。所以监控CPU的使用情况,能够获知系统瓶颈的变化,以及在发现问题时,是否可以通过水平扩展机器数来解决问题。
网络监控
网络监控通常指的是服务器网路监控,用于定位服务器网络瓶颈,通常看TCP的重传率,内部网络重传率超过1%,往往会造成访问延迟增加。
网络监控包含以下关键指标:
- TCPretr
- 网络I/O
- TCP连接数
内存监控
系统的内存不足引发磁盘交换,很可能使内存成为“木桶短板”。
内存监控包含以下关键指标:
- 内存的使用量:物理内存的使用量
- swap I/O:交换到磁盘的量,常常是因为内存不够才发生的
磁盘监控
磁盘I/O性能监控指标如下
- 磁盘利用率(Utilization)
- 服务时间(Service Time)
- I/O 等待队列长度(Queue Length)
- 等待时间(Wait Time)
参考:《大型网站性能优化实战》